#apache zookeeper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
Apache Kafka, the open-source, distributed event streaming platform, has been a game-changer in the world of data processing and integration.
0 notes
Text
🌟 What is Apache ZooKeeper?
Apache ZooKeeper is an open-source coordination service designed to manage distributed applications. It provides a centralized service for maintaining configuration information, naming, and providing distributed synchronization. Essentially, it helps manage large-scale distributed systems and ensures they operate smoothly and reliably.
Key Features of ZooKeeper:
Centralized Service: Manages and maintains configuration and synchronization information across a distributed system.
High Availability: Ensures that distributed systems are resilient to failures by providing fault tolerance and replication.
Consistency: Guarantees a consistent view of the configuration and state across all nodes in the system.
Benefits of Using Apache ZooKeeper:
Enhanced Coordination: Simplifies coordination between distributed components and helps manage critical information like leader election, distributed locks, and configuration management.
Improved Fault Tolerance: By replicating data across multiple nodes, ZooKeeper ensures that even if one node fails, the system can continue to function with minimal disruption.
Scalable Architecture: Supports scaling by allowing systems to expand and manage increasing loads without compromising performance or reliability.
Strong Consistency: Provides a strong consistency model, ensuring that all nodes in the distributed system have a consistent view of the data, which is crucial for maintaining system integrity.
Simplified Development: Abstracts the complexities of distributed system coordination, allowing developers to focus on business logic rather than the intricacies of synchronization and configuration management.
Efficient Resource Management: Helps in managing distributed resources efficiently, making it easier to handle tasks like service discovery and distributed locking.
Apache ZooKeeper is a powerful tool for anyone working with distributed systems, making it easier to build and maintain robust, scalable, and fault-tolerant applications. Whether you’re managing a large-scale enterprise application or a complex microservices architecture, ZooKeeper can provide the coordination and consistency you need.
If you’re looking for Apache ZooKeeper consultants to enhance your distributed system's coordination and reliability, don’t hesitate to reach out to us. Our team of specialists has extensive experience with ZooKeeper and can help you implement and optimize its capabilities for your unique needs. Contact us today to discuss how we can support your projects and ensure your systems run smoothly and efficiently.
2 notes
·
View notes
Text
Running Latest Kafka Without Zookeeper
Complete Step-by-Step Guide to Setting Up Kafka (KRaft Mode) Locally 1. Extract Kafka Files Step 1: Download the latest version of Apache Kafka (e.g., 2.13-4.0.0) from the official Apache Kafka website. Step 2: Extract the Kafka zip file to a location on your machine. For example: D:\kafka_2.13-4.0.0 2. Generate the GUID (for KRaft mode) Kafka needs a unique identifier (GUID) for its storage…
0 notes
Text
0 notes
Text
Real-Time Data Streaming: How Apache Kafka is Changing the Game
Introduction
In today’s fast-paced digital world, real-time data streaming has become more essential than ever because businesses now rely on instant data processing to make data-driven and informed decision-making. Apache Kafka, i.e., a distributed streaming platform for handling data in real time, is at the heart of this revolution. Whether you are an Apache Kafka developer or exploring Apache Kafka on AWS, this emerging technology can change the game of managing data streams. Let’s dive deep and understand how exactly Apache Kafka is changing the game.
Rise of Real-Time Data Streaming
The vast amount of data with businesses in the modern world has created a need for systems to process and analyze as it is produced. This amount of data has emerged due to the interconnections of business with other devices like social media, IoT, and cloud computing. Real-time data streaming enables businesses to use that data to unlock vast business opportunities and act accordingly.
However, traditional methods fall short here and are no longer sufficient for organizations that need real-time data insights for data-driven decision-making. Real-time data streaming requires a continuous flow of data from sources to the final destinations, allowing systems to analyze that information in less than milliseconds and generate data-driven patterns. However, building a scalable, reliable, and efficient real-time data streaming system is no small feat. This is where Apache Kafka comes into play.
About Apache Kafka
Apache Kafka is an open-source distributed event streaming platform that can handle large real-time data volumes. It is an open-source platform developed by the Apache Software Foundation. LinkedIn initially introduced the platform; later, in 2011, it became open-source.
Apache Kafka creates data pipelines and systems to manage massive volumes of data. It is designed to manage low-latency, high-throughput data streams. Kafka allows for the injection, processing, and storage of real-time data in a scalable and fault-tolerant way.
Kafka uses a publish-subscribe method in which:
Data (events/messages) are published to Kafka topics by producers.
Consumers read and process data from these subjects.
The servers that oversee Kafka's message dissemination are known as brokers.
ZooKeeper facilitates the management of Kafka's leader election and cluster metadata.
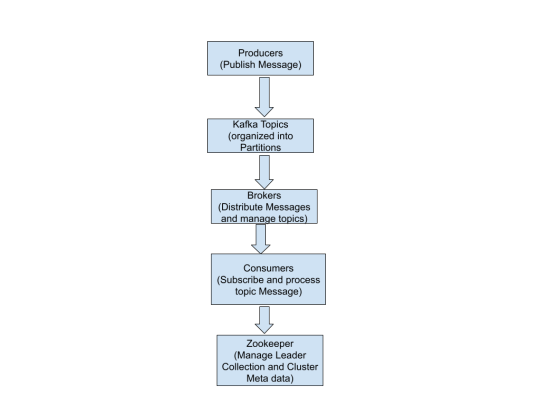
With its distributed architecture, fault tolerance, and scalability, Kafka is a reliable backbone for real-time data streaming and event-driven applications, ensuring seamless data flow across systems.
Why Apache Kafka Is A Game Changer
Real-time data processing helps organizations collect, process, and even deliver the data as it is generated while immediately ensuring the utmost insights and actions. Let’s understand the reasons why Kafka stands out in the competitive business world:
Real-Time Data Processing
Organizations generate vast amounts of data due to their interconnection with social media, IoT, the cloud, and more. This has raised the need for systems and tools that can react instantly and provide timely results. Kafka is a game-changer in this regard. It helps organizations use that data to track user behavior and take action accordingly.
Scalability and Fault Tolerance
Kafka's distributed architecture guarantees data availability and dependability even in the case of network or hardware failures. It is a reliable solution for mission-critical applications because it ensures data durability and recovery through replication and persistent storage.
Easy Integration
Kafka seamlessly connects with a variety of systems, such as databases, analytics platforms, and cloud services. Its ability to integrate effortlessly with these tools makes it an ideal solution for constructing sophisticated data pipelines.
Less Costly Solution
Kafka helps in reducing the cost of data processing and analyzing efficiently and ensures high performance of the businesses. By handling large volumes of data, Kafka also enhances scalability and reliability across distributed systems.
Apache Kafka on AWS: Unlocking Cloud Potential
Using Apache Kafka on ASW has recently become more popular because of the cloud’s advantages, like scalability, flexibility, and cost efficiency. Here, Kafka can be deployed in a number of ways, such as:
Amazon MSK (Managed Streaming for Apache Kafka): A fully managed service helps to make the deployment and management of Kafka very easy. Additionally, it handles infrastructure provisioning, scaling, and even maintenance and allows Apache Kafka developers to focus on building applications.
Self-Managed Kafka on EC2: This is apt for organizations that prefer full control of their Kafka clusters, as AWS EC2 provides the flexibility to deploy and manage Kafka instances.
The benefits of Apache Kafka on ASW are as follows:
Easy scaling of Kafka clusters as per the demand.
Ensures high availability and enables disaster recovery
Less costly because it uses a pay-as-you-go pricing model
The Future of Apache Kafka
Kafka’s role in the technology ecosystem will definitely grow with the increase in the demand for real-time data processing. Innovations like Kafka Streams and Kafka Connect are already expanding the role of Kafka and making real-time processing quite easy. Moreover, integrations with cloud platforms like AWS continuously drive the industry to adopt Kafka within different industries and expand its role.
Conclusion
Apache Kafka is continuously revolutionizing the organizations of modern times that are handling real-time data streaming and changing the actual game of businesses around the world by providing capabilities like flexibility, scalability, and seamless integration. Whether you are deploying Apache Kafka on AWS or working as an Apache Kafka developer, this technology can offer enormous possibilities for innovation in the digitally enabled business landscape.
Do you want to harness the full potential of your Apache Kafka systems? Look no further than Ksolves, where a team of seasoned Apache Kafka experts and developers stands out as a leading Apache Kafka development company with their client-centric approach and a commitment to excellence. With our extensive experience and expertise, we specialize in offering top-notch solutions tailored to your needs.
Do not let your data streams go untapped. Partner with leading partners like Ksolves today!
Visit Ksolves and get started!
#kafka apache#apache kafka on aws#apache kafka developer#apache cassandra consulting#certified developer for apache kafka
0 notes
Text
Navigating the Data World: A Deep Dive into Architecture of Big Data Tools

In today’s digital world, where data has become an integral part of our daily lives. May it be our phone’s microphone, websites, mobile applications, social media, customer feedback, or terms & conditions – we consistently provide “yes” consents, so there is no denying that each individual's data is collected and further pushed to play a bigger role into the decision-making pipeline of the organizations.
This collected data is extracted from different sources, transformed to be used for analytical purposes, and loaded in another location for storage. There are several tools present in the market that could be used for data manipulation. In the next sections, we will delve into some of the top tools used in the market and dissect the information to understand the dynamics of this subject.
Architecture Overview
While researching for top tools, here are a few names that made it to the top of my list – Snowflake, Apache Kafka, Apache Airflow, Tableau, Databricks, Redshift, Bigquery, etc. Let’s dive into their architecture in the following sections:
Snowflake
There are several big data tools in the market serving warehousing purposes for storing structured data and acting as a central repository of preprocessed data for analytics and business intelligence. Snowflake is one of the warehouse solutions. What makes Snowflake different from other solutions is that it is a truly self-managed service, with no hardware requirements and it runs completely on cloud infrastructure making it a go-to for the new Cloud era. Snowflake uses virtual computing instances and a storage service for its computing needs. Understanding the tools' architecture will help us utilize it more efficiently so let’s have a detailed look at the following pointers:

Image credits: Snowflake
Now let’s understand what each layer is responsible for. The Cloud service layer deals with authentication and access control, security, infrastructure management, metadata, and optimizer manager. It is responsible for managing all these features throughout the tool. Query processing is the compute layer where the actual query computation happens and where the cloud compute resources are utilized. Database storage acts as a storage layer for storing the data.
Considering the fact that there are a plethora of big data tools, we don’t shed significant light on the Apache toolkit, this won’t be justice done to their contribution. We all are familiar with Apache tools being widely used in the Data world, so moving on to our next tool Apache Kafka.
Apache Kafka
Apache Kafka deserves an article in itself due to its prominent usage in the industry. It is a distributed data streaming platform that is based on a publish-subscribe messaging system. Let’s check out Kafka components – Producer and Consumer. Producer is any system that produces messages or events in the form of data for further processing for example web-click data, producing orders in e-commerce, System Logs, etc. Next comes the consumer, consumer is any system that consumes data for example Real-time analytics dashboard, consuming orders in an inventory service, etc.
A broker is an intermediate entity that helps in message exchange between consumer and producer, further brokers have divisions as topic and partition. A topic is a common heading given to represent a similar type of data. There can be multiple topics in a cluster. Partition is part of a topic. Partition is data divided into small sub-parts inside the broker and every partition has an offset.
Another important element in Kafka is the ZooKeeper. A ZooKeeper acts as a cluster management system in Kafka. It is used to store information about the Kafka cluster and details of the consumers. It manages brokers by maintaining a list of consumers. Also, a ZooKeeper is responsible for choosing a leader for the partitions. If any changes like a broker die, new topics, etc., occur, the ZooKeeper sends notifications to Apache Kafka. Zookeeper has a master-slave that handles all the writes, and the rest of the servers are the followers who handle all the reads.
In recent versions of Kafka, it can be used and implemented without Zookeeper too. Furthermore, Apache introduced Kraft which allows Kafka to manage metadata internally without the need for Zookeeper using raft protocol.

Image credits: Emre Akin
Moving on to the next tool on our list, this is another very popular tool from the Apache toolkit, which we will discuss in the next section.
Apache Airflow
Airflow is a workflow management system that is used to author, schedule, orchestrate, and manage data pipelines and workflows. Airflow organizes your workflows as Directed Acyclic Graph (DAG) which contains individual pieces called tasks. The DAG specifies dependencies between task execution and task describing the actual action that needs to be performed in the task for example fetching data from source, transformations, etc.
Airflow has four main components scheduler, DAG file structure, metadata database, and web server. A scheduler is responsible for triggering the task and also submitting the tasks to the executor to run. A web server is a friendly user interface designed to monitor the workflows that let you trigger and debug the behavior of DAGs and tasks, then we have a DAG file structure that is read by the scheduler for extracting information about what task to execute and when to execute them. A metadata database is used to store the state of workflow and tasks. In summary, A workflow is an entire sequence of tasks and DAG with dependencies defined within airflow, a DAG is the actual data structure used to represent tasks. A task represents a single unit of DAG.

As we received brief insights into the top three prominent tools used by the data world, now let’s try to connect the dots and explore the Data story.
Connecting the dots
To understand the data story, we will be taking the example of a use case implemented at Cubera. Cubera is a big data company based in the USA, India, and UAE. The company is creating a Datalake for data repository to be used for analytical purposes from zero-party data sources as directly from data owners. On an average 100 MB of data per day is sourced from various data sources such as mobile phones, browser extensions, host routers, location data both structured and unstructured, etc. Below is the architecture view of the use case.

Image credits: Cubera
A node js server is built to collect data streams and pass them to the s3 bucket for storage purposes hourly. While the airflow job is to collect data from the s3 bucket and load it further into Snowflake. However, the above architecture was not cost-efficient due to the following reasons:
AWS S3 storage cost (for each hour, typically 1 million files are stored).
Usage costs for ETL running in MWAA (AWS environment).
The managed instance of Apache Airflow (MWAA).
Snowflake warehouse cost.
The data is not real-time, being a drawback.
The risk of back-filling from a sync-point or a failure point in the Apache airflow job functioning.
The idea is to replace this expensive approach with the most suitable one, here we are replacing s3 as a storage option by constructing a data pipeline using Airflow through Kafka to directly dump data to Snowflake. The following is a newfound approach, as Kafka works on the consumer-producer model, snowflake works as a consumer here. The message gets queued on the Kafka topic from the sourcing server. The Kafka for Snowflake connector subscribes to one or more Kafka topics based on the configuration information provided via the Kafka configuration file.

Image credits: Cubera
With around 400 million profile data directly sourced from individual data owners from their personal to household devices as Zero-party data, 2nd Party data from various app partnerships, Cubera Data Lake is continually being refined.
Conclusion
With so many tools available in the market, choosing the right tool is a task. A lot of factors should be taken into consideration before making the right decision, these are some of the factors that will help you in the decision-making – Understanding the data characteristics like what is the volume of data, what type of data we are dealing with - such as structured, unstructured, etc. Anticipating the performance and scalability needs, budget, integration requirements, security, etc.
This is a tedious process and no single tool can fulfill all your data requirements but their desired functionalities can make you lean towards them. As noted earlier, in the above use case budget was a constraint so we moved from the s3 bucket to creating a data pipeline in Airflow. There is no wrong or right answer to which tool is best suited. If we ask the right questions, the tool should give you all the answers.
Join the conversation on IMPAAKT! Share your insights on big data tools and their impact on businesses. Your perspective matters—get involved today!
0 notes
Text
Designing a Scalable Blockchain Network with Java and ZooKeeper
Creating a Scalable Java-based Blockchain Network with ZooKeeper Introduction In this tutorial, we will explore the process of creating a scalable Java-based blockchain network using Apache ZooKeeper. A blockchain network is a decentralized system that allows multiple nodes to work together to validate and record transactions in a secure and transparent manner. Apache ZooKeeper is a centralized…
0 notes
Text
Apache Storm Tutorial: Real-Time Analytics and Stream Processing Explained

Apache Storm is a powerful tool for real-time data processing, making it ideal for applications that need instant data insights. Whether you’re analyzing social media feeds, processing transactions, or managing sensor data, Apache Storm can help handle vast amounts of data efficiently.
To get started, you need to understand a few key concepts. Apache Storm is designed around “spouts” and “bolts”. Spouts are the entry points that fetch data from sources like social media streams or databases. Bolts, on the other hand, are the processors, responsible for analyzing and transforming the data received from spouts. Together, these components create a "topology," which defines how data flows through the system.
Setting up Apache Storm requires installing Java and setting up ZooKeeper, which coordinates the various components in a distributed environment. Once installed, you can start creating and deploying topologies. Each topology runs indefinitely until you decide to stop it, allowing for continuous data processing.
One of Apache Storm’s biggest strengths is its scalability. It can process millions of messages per second, which makes it perfect for real-time analytics. Additionally, Apache Storm works well with other big data tools like Apache Hadoop, making it versatile for various data projects.
If you’re looking to learn more about using Apache Storm, check out the complete Apache Storm Tutorial from TAE. This guide provides detailed insights and examples to help you master Apache Storm and start building powerful data-driven applications.
0 notes
Text
ECE 454 Assignment 3: Fault Tolerance solved
Overview • In this assignment, you will implement a fault-tolerant keyvalue storage system. • A partial implementation of the key-value service and a full implementation of the client are provided in the starter code tarball. • Your goal is to add primary-backup replication to the keyvalue service using Apache ZooKeeper for coordination. • ZooKeeper will be used to solve two problems: 1.…
0 notes
Text
ECE 454 Assignment 3: Fault Tolerance
Overview • In this assignment, you will implement a fault-tolerant keyvalue storage system. • A partial implementation of the key-value service and a full implementation of the client are provided in the starter code tarball. • Your goal is to add primary-backup replication to the keyvalue service using Apache ZooKeeper for coordination. • ZooKeeper will be used to solve two problems: 1.…
0 notes
Link
0 notes
Text
Hadoop Eco System

The Hadoop ecosystem is a framework and suite of technologies for handling large-scale data processing and analysis. It’s built around the Hadoop platform, which provides the essential infrastructure for storing and processing big data. The ecosystem includes various tools and technologies that complement and extend Hadoop’s capabilities. Key components include:
Hadoop Distributed File System (HDFS): A distributed file system that provides high-throughput access to application data. It’s designed to store massive data sets reliably and to stream those data sets at high bandwidth to user applications.
MapReduce: A programming model and processing technique for distributed computing. It processes large data sets with a parallel, distributed algorithm on a cluster.
YARN (Yet Another Resource Negotiator): Manages and monitors cluster resources and provides a scheduling environment.
Hadoop Common: The standard utilities that support other Hadoop modules.
Pig: A platform for analyzing large data sets. Pig uses a scripting language named Pig Latin.
Hive: A data warehouse infrastructure built on top of Hadoop for providing data summarization, query, and analysis.
HBase: A scalable, distributed database that supports structured data storage for large tables.
Sqoop: A tool designed for efficiently transferring bulk data between Apache Hadoop and structured data stores such as relational databases.
Zookeeper: A centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Oozie: A workflow scheduler system to manage Hadoop jobs.
Flume: A distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
Apache Spark: An open-source, distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Although Spark is part of the broader Hadoop ecosystem, it does not use the MapReduce paradigm for data processing; it has its own distributed computing framework.
These components are designed to provide a comprehensive ecosystem for processing large volumes of data in various ways, including batch processing, real-time streaming, data analytics, and more. The Hadoop ecosystem is widely used in industries for big data analytics, including finance, healthcare, media, retail, and telecommunications.
Hadoop Training Demo Day 1 Video:
youtube
You can find more information about Hadoop Training in this Hadoop Docs Link
Conclusion:
Unogeeks is the №1 IT Training Institute for Hadoop Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Hadoop Training here — Hadoop Blogs
Please check out our Best In Class Hadoop Training Details here — Hadoop Training
S.W.ORG
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#unogeeks #training #ittraining #unogeekstraining
0 notes
Text
Real-time Data Processing with Apache Kafka

Apache Kafka is a distributed, real-time data streaming platform that is designed for handling large volumes of data and providing a reliable, scalable, and high-throughput way to ingest, process, and distribute data in real-time. It was originally developed by LinkedIn and later open-sourced as an Apache project.
Real-time data processing with Apache Kafka involves several key concepts and components:
Topics: Data is organized into topics, which are logical channels or feeds where producers write data and consumers read from. Topics allow for the categorization and partitioning of data streams.
Producers: Producers are responsible for sending data to Kafka topics. They can be various data sources such as applications, IoT devices, or log files. Producers publish messages to Kafka topics, and Kafka stores these messages for a defined retention period.
Brokers: Kafka brokers are the servers that make up the Kafka cluster. They receive, store, and distribute messages. A Kafka cluster typically consists of multiple brokers to provide scalability and fault tolerance.
Partitions: Each topic is divided into one or more partitions. Partitions are the unit of parallelism in Kafka and allow for horizontal scaling. Messages within a partition are strictly ordered, but across partitions, there is no guaranteed order.
Consumers: Consumers read data from Kafka topics. They can subscribe to one or more topics and consume messages from one or more partitions within those topics. Consumers can be part of a consumer group for load balancing and parallel processing.
Consumer Groups: Consumers can be organized into consumer groups to distribute the work of processing messages. Each partition is consumed by only one member of a consumer group, which enables parallel processing.
ZooKeeper: ZooKeeper is used for managing and coordinating Kafka brokers in older versions of Kafka (prior to version 2.8.0). In Kafka 2.8.0 and later, ZooKeeper has been replaced by the Kafka Raft Metadata Quorum (KRaft).
Real-time data processing with Apache Kafka involves the following steps:
Data Ingestion: Producers send data to Kafka topics. Kafka ensures that the data is durably stored and replicated across multiple brokers.
Data Processing: Consumers subscribe to one or more topics, read data from Kafka, and process it. This processing can involve various tasks such as data transformation, enrichment, and analysis.
Scalability: Kafka provides horizontal scalability by allowing you to add more brokers and partitions to handle increased data loads. Consumers can be organized into consumer groups for load distribution.
Reliability: Kafka provides built-in fault tolerance by replicating data across multiple brokers. If a broker or consumer fails, data can still be retrieved from other replicas or consumers.
Real-time Analytics: Kafka can be integrated with various analytics and processing frameworks like Apache Spark, Apache Flink, or stream processing libraries to perform real-time data analysis and decision-making.
1 note
·
View note
Text
0 notes
Quote
2014 年に遡ると、私はイベント処理エンジンのコアを再構築していました。 当時の決定は、Apache Kafka を使用するか、独自のカフカを導入するかでした。 Zookeeper を調査した後、オンプレミスの顧客はおそらく Zookeeper を所有して管理することを望まなかったため、独自のサービスを導入することを決定し、メッセージング レイヤーとして ZeroMQ を選択しました。 ZeroMQ は完全に堅牢で安定していました。 信じられないほどトラブルが少なく、私たちが遭遇した唯一の問題は、構成手順に記載したポートを IT チームが開かなかったときでした。 (結果として得られるアーキテクチャは実際には Flink によく似ています) いずれにせよ、ZeroMQ は素晴らしいテクノロジーですが、あまり世の中に出回っていない���うな気がします。 私の経験から言うと、非常にシンプルで信じられないほど安定しています。
ZeroMQ – LGPL3 からの再ライセンスと MPL 2.0 の例外 | ハッカーニュース
1 note
·
View note